Editor's Note: Take a look at our featured best practice, Agentic AI Playbook (562-slide PowerPoint presentation). Curated by McKinsey-trained Executives
Unlock the Future of Business with the Ultimate Agentic AI Playbook: The Only Resource You'll Ever Need to Dominate the AI Revolution
In today's fast-paced, tech-driven world, the companies that stay ahead of the curve are the ones that fully [read more]
* * * *
Artificial Intelligence (AI) agents that can reason, act, and improve in real time are not science fiction anymore—but neither are they ready for prime time without serious scrutiny. The Agentic AI Assessment Framework steps in as a structured approach to evaluate whether autonomous agents are just flashy demos or truly enterprise-grade contributors.
Traditional AI workflows are deterministic and brittle. They rely on predefined prompt chains and struggle in volatile environments. Autonomous agents flip that script. These agents are tasked with goals rather than steps. They reason, plan, act independently, learn from outcomes, and adapt. They are not just automating—they are operating. But that kind of autonomy demands new guardrails. The Agentic AI Assessment framework gives executives a practical way to benchmark an AI agent’s real-world Performance and identify where the gaps are hiding.
Take the meteoric rise of AI copilots across productivity suites. Whether it’s writing, coding, or summarizing, vendors are racing to ship agents that “do the work.” But most of what’s out there still fails under pressure—especially when facing vague tasks, unstructured data, or unexpected scenarios. The Agentic AI Assessment Framework provides a diagnostic lens to separate marketing hype from operational reality, giving leaders a rubric to assess agent capabilities before scaling deployment.
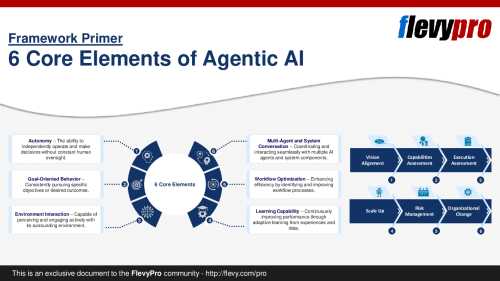
The framework is built on 6 core phases that evaluate the performance maturity of an AI agent:
Reasoning and Planning
Task Autonomy and Execution
Memory and Knowledge
Reliability and Safety
Integration and Interoperability
Social Understanding
Why This Framework Matters Now
Most organizations are still thinking of AI agents like sophisticated chatbots. That framing is broken. These agents are not just text interfaces—they’re software operators navigating systems, data, and users. To trust them with meaningful work, organizations must shift from toy metrics to rigorous assessments. The Agentic AI Assessment Framework forces that shift. It creates a shared language between technical teams and leadership about what readiness really means.
The Agentic AI Assessment framework forces teams to test agents in operational conditions—ambiguity, tool complexity, regulatory constraints, and shifting goals. The result is a more grounded, accurate picture of where AI agents are usable and where they are still fragile. For Strategy and IT teams, this insight becomes a compass for deciding where to invest, where to wait, and what infrastructure is missing.
The biggest value might be in the de-risking. As organizations move from pilots to scale, failure modes become costlier. AI agents that hallucinate, misread instructions, or can’t complete workflows can create legal, brand, and customer risks. The Agentic AI Assessment framework provides the kind of structure that audit committees, security leads, and Digital Transformation leaders need to move forward confidently.
It also unlocks clarity in vendor decisions. With every platform pitching AI agents as the next frontier, decision makers need a structured evaluation model that goes beyond benchmark tests. This framework becomes the template for scorecards, RFPs, and roadmap prioritization.
For now, let us take a closer look at the first two elements of the Agentic AI Assessment framework.
Reasoning and Planning
This is the brain of the operation. It is where an AI agent interprets a goal, figures out what to do, breaks it into steps, and decides how to proceed. Most agents today struggle here. They hallucinate logic, skip steps, and often misinterpret ambiguous goals. Without reliable reasoning, agents are glorified suggestion machines.
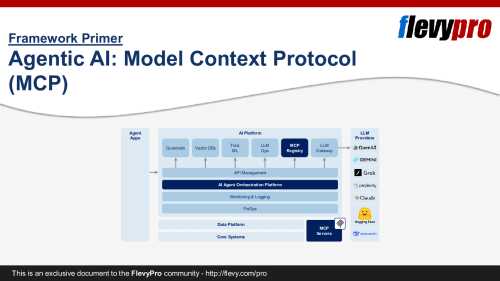
To make this capability real, agents need richer tool access and support during inference, instead of just smarter prompts. The Model Context Protocol (MCP), a supporting system architecture, helps by offering structured context, tool registries, and reusable planning templates. But let us be honest—without better reasoning, agents won’t graduate from demo mode.
Task Autonomy and Execution
This is where ideas meet action. Once a plan is in place, can the agent do the work without handholding? Most cannot. Execution maturity is low, even among the most hyped tools. Autonomy means picking tools, running tasks across systems, handling errors, and seeing things through.
The gap here is less about model capability and more about orchestration. MCP plays a heavy role—it connects tools, coordinates workflows, and enables real-time API invocation. When this works, agents stop being passive advisors and start acting like digital employees. But until governance, rollback, and safety controls catch up, this phase will remain a bottleneck for production use.
Case Study
Imagine an AI agent embedded in a CRM system. Its goal is to increase lead conversion by automating follow-ups, summarizing meetings, and recommending next best actions. Here is how the Agentic AI Assessment framework applies:
It struggles with Reasoning and Planning when goals are vague—like “re-engage dormant accounts.” It often generates boilerplate without context.
Execution is brittle. It can send emails but can’t reliably adjust tone based on customer history or coordinate across tools.
It forgets meeting context unless explicitly re-prompted, as memory and knowledge are paper-thin.
Reliability is hit or miss. It sometimes mislabels leads or suggests deals that already closed.
Integration is passable—it connects to the CRM, but workflows break when data formats shift.
Social Understanding is nonexistent. Customers feel like they are talking to a robot from 2016.
The takeaway: without rigorous assessment, this agent looks impressive in demos but underperforms in the wild. The Agentic AI Assessment framework reveals these operational deltas before reputational damage hits.
FAQs
What’s the biggest blocker to deploying agentic AI in production?
Execution. Most agents cannot reliably perform tasks across real-world systems, especially when tools, data, and conditions change midstream.
How does the Agentic AI Assessment framework help?
It acts as connective tissue—giving agents standardized access to tools, data sources, and system protocols. It fills major gaps in reasoning, execution, memory, and interoperability.
Why are reasoning capabilities still so weak?
Because current models rely too much on prompt design. They lack native inference-time reasoning that adjusts dynamically based on feedback and environment.
Can an agent be strong in one capability but still unusable?
Absolutely. A brilliant planner that can’t execute is just a strategist without a team. All six phases of the Agentic AI Assessment framework must meet a minimum bar to move from proof-of-concept to real deployment.
Is social understanding just a UX nice-to-have?
Not at all. It’s a gatekeeper for trust. Without it, agents cannot participate in advisory, sensitive, or customer-facing work.
Closing Thoughts
AI Strategy is moving from hype cycles to production realities—and the Agentic AI Assessment framework is how to close that gap. But here is what no one is saying: most organizations will realize they do not have a tech problem, they have an evaluation problem. Their internal scorecards are built for dashboards and data lakes, not autonomous decision-makers.
Want to know if your agents are ready? Run them through the Agentic AI Assessment framework. Be ruthless. Strip out the demos. Test real tasks. This isn’t about crushing ambition—it’s about building credibility.
You can download in-depth presentations on this and hundreds of similar business frameworks from the FlevyPro Library. FlevyPro is trusted and utilized by 1000s of management consultants and corporate executives.
For even more best practices available on Flevy, have a look at our top 100 lists:
Agentic AI represents a shift toward autonomous, intelligent systems that can make decisions and take actions with minimal human intervention. Evolving from traditional machine learning, this technology enhances operations by automating complex workflows, optimizing decision-making, and enabling [read more]
Readers of This Article Are Interested in These Resources
As AI agents spread across organizations, they need access to the tools where work and data already live. Connecting agents to databases, project management platforms, ERP suites, CRM systems, and similar applications remains a major integration hurdle.
This slide deck provides a detailed [read more]
Agentic AI addresses a critical challenge in enterprise adoption: while most organizations achieve early success with individual models, few connect them into cohesive systems that transform business performance.
Traditional automation improves efficiency, yet it rarely redefines how decisions [read more]
Curated by McKinsey-trained Executives
100+ Agentic Organization SOPs Library
Complete AI-First Operating System -- Delivered in a Scalable Excel Template
Build, govern, and scale a fully Agentic Organization with confidence.
This 100+ Agentic Organization SOPs Library is a [read more]
Most organizations have realized wins by developing AI and analytics capabilities. The challenge is scaling those wins so they are seen in operations, customer experience and financial results, however, tools alone rarely deliver that outcome.
An Agentic AI Strategy focuses on building the [read more]